关于DeepSeek v4,你需要知道的几件事儿
2026年4月24日,DeepSeek v4发布,DeepSeek v4到底做了哪些事情?能力如何?本文给你讲清楚。
1. deepseek-v4 模型的能力如何?
论文中对DeepSeek-v4 模型分成了四部分来介绍,分别是(世界)知识、推理能力、Agent、长上下文。原文是这么说的:


客观的说:
- 知识层面,与Gemini-3.1-pro 仍有差距;
- 推理能力上,与顶级模型GPT-5.4、Gemini-3.1-pro的差距大概在3~6个月。水平大概与GPT-5.2、Gemini-3.0-pro 相当;
- Agent:与Kimi-K2.6、GLM-5.1 相当。但是稍微差于顶级的闭源模型;
- 长上下文:在1M token上下文的背景下,效果甚至超过了Gemini-3.1-Pro
2. DeepSeek v4有哪些版本?
DeepSeek v4有两大版本,分别是flash与pro。在flash与pro版本下,又各有一个test-time scaling 的版本,即:flash-max 与 pro-max。一图看懂:
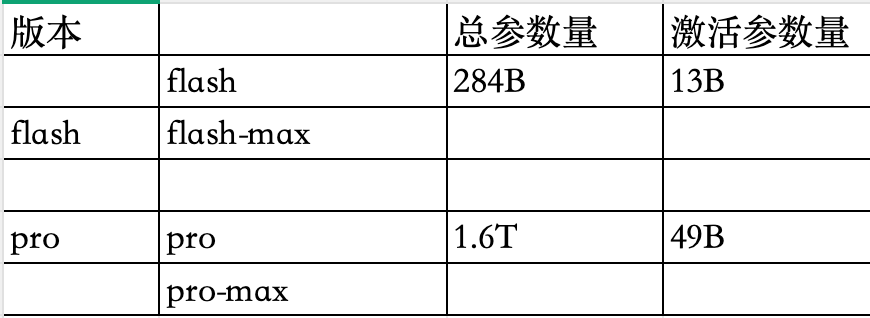
简单来说,deepseek-v4-pro-max 就是DeepSeek-v4-pro 做出极限思考下的版本。
3. deepseek-v4 的初衷是什么?
DeepSeek v4的初衷是:解决长上下文推理问题。
当前各个模型通常会采取test-time scaling 方法来提升模型在推理时的效果,但是test-time scaling存在一个问题:推理时输出的长context会导致计算和内存疯狂暴涨,其复杂程度是
级别。
鉴于推理时耗时耗内存的问题,DeepSeek-v4 给出的解决方案是:极致压缩Attention。怎么极致压缩呢?文章提出了两种方法,分别是CSA(Compressed Sparse Attention)和 HCA(Heavliy Compressed Attention)。
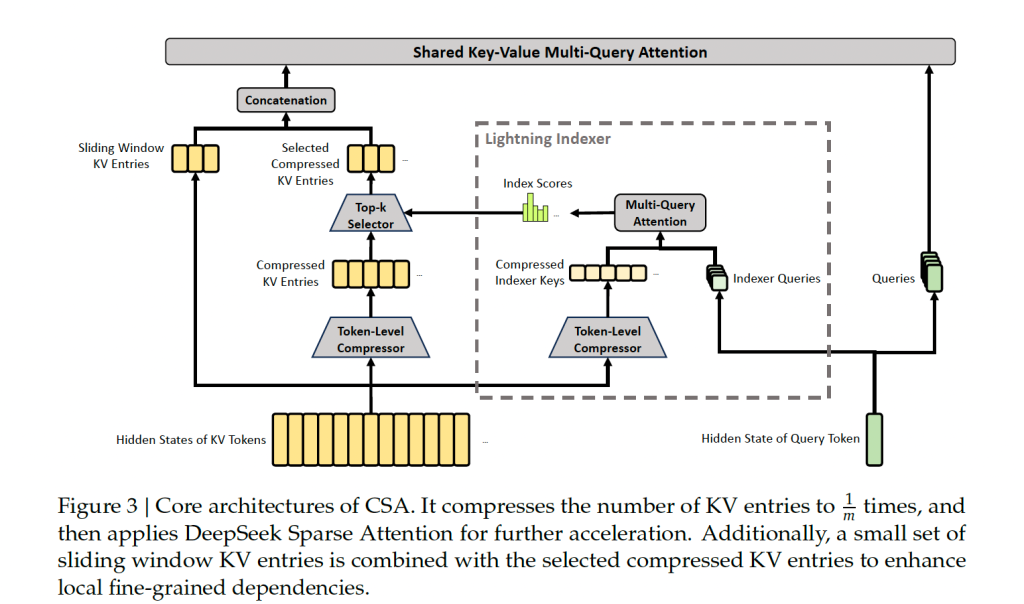
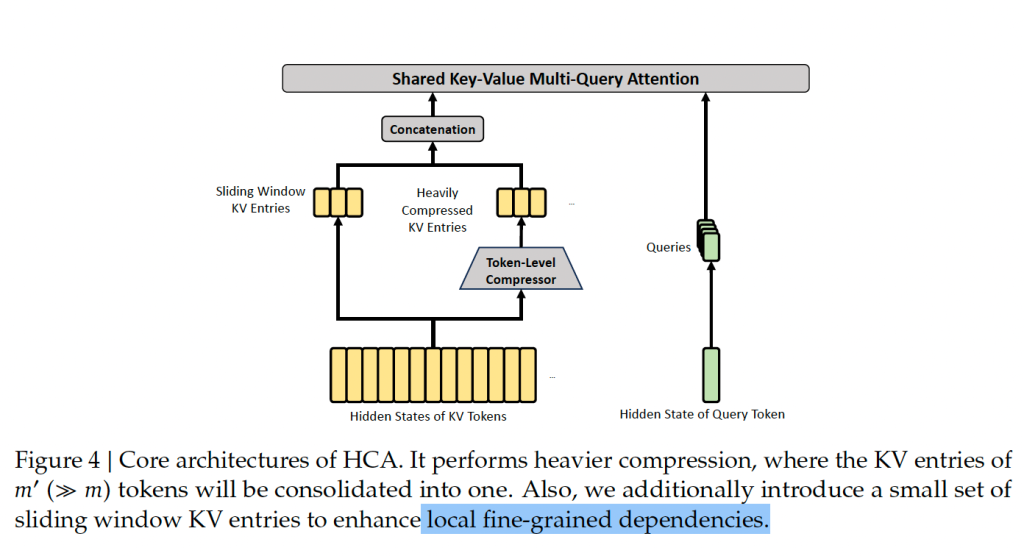
这两种Attention方法的核心思想是完全一致的:就是基于Attention再做Attention。这么做完之后,就实现了DeepSeek-v4的初衷:通过极致的压缩长下文,实现了长下文下的性能极致发挥。从而做到极致的性价比。
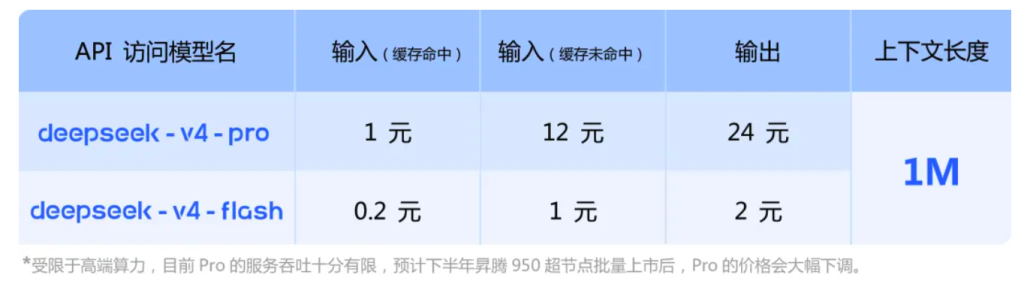
所以,DeepSeek-v4 最大的意义在于大模型平权。
4. DeepSeek-v4 系列的预训练
deepseek-v4 的预训练表明:即使使用预训练的方式,只要模型结构设计良好且高效,那么也会取得非常不错的效果。
DeepSeek-V4-Flash 使用 32T tokens ,DeepSeek-V4-Pro 使用 33T tokens 进行预训练。
经过预训练后,DeepSeek-v4-Flash-Base 的效果就已经超过了DeepSeek-V3.2-Base。这表明:v4的模型设计是更加高效的。更离谱的是,Deepseek-v4-Pro-base 进一步放大了这个收益,直接达到了DeepSeek基座模型的新巅峰水平——在推理、编码、长上下文、世界知识任务中都有全面优势
5. DeepSeek-v4 系列的后训练
选择了两阶段训练的范式:
- stage 1:独立地训练领域专家;
具体地,先通过SFT的方式过领域内数据,如数学、代码、Agent的数据;然后使用GRPO的方式优化模型领域内对齐的行为。
- stage 2:通过on-policy 蒸馏联合训练模型的整合。
通过KL损失来学习各个领域专家模型的能力。
6. Deepseek-v4 的模型架构
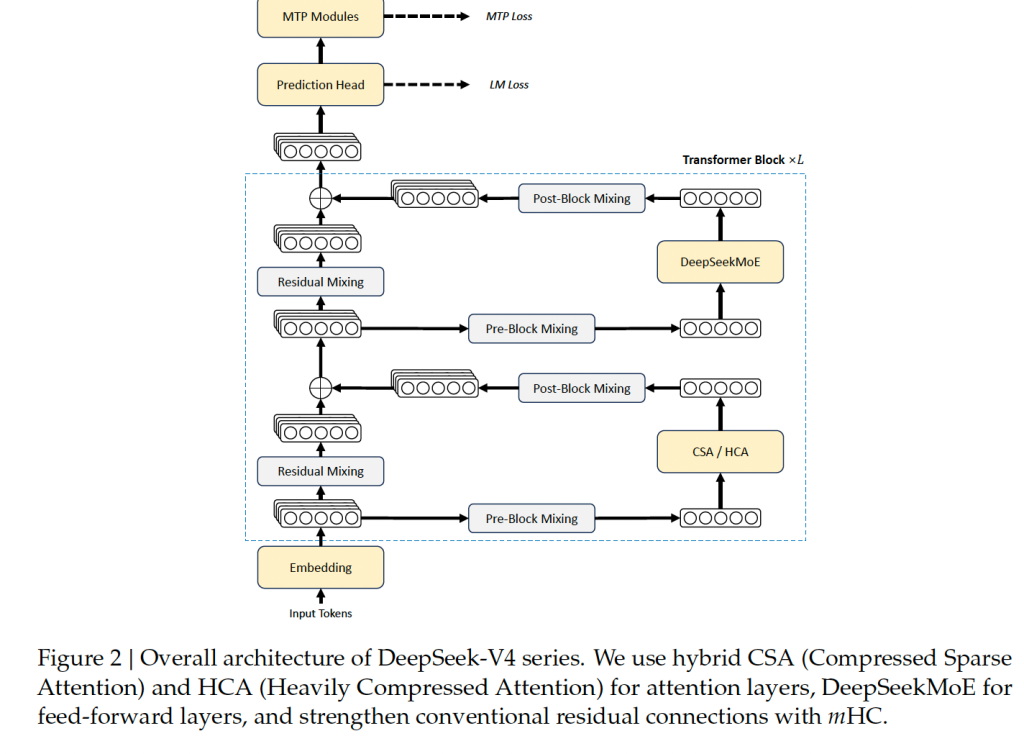
模型架构中主要使用了下面这些算法or优化:
- 继承自V3的MOE、MTP方式
MTP在DeepSeek-V3中已经被证明有效,所以仍然保留。MTP应该会成为后续模型的主流。
- 混合Attention:CSA与HCA、MQA、Sliding Window Attention
Attention 是LLM/VLM中最重要的结构,可以说,任何一个大模型最重要的部件就是Attention。为了各种目的优化,会对Attention做更改。比如本paper使用的几种Attention。
- Attention sink
这个算法的思想其实就是调整Attention score的值。这么做的原因是:实验发现,一串embedding的Attention值通常集中在头部,为了避免这种sink(下沉)现象,就对Attention值做了一个修正:

其实就是加上了这个
,这样就会让最后的Attention score加和不是1。