虽迟但到,Kimi2.5终于支持多模态了!
Kimi 2.5最大的创新在于提出了Agent swarm机制。通过Agent Swarm,可以将复杂的问题迅速拆解成简单的多个问题来并行执行,极大地提升了问题解决的效率。Agent Swarm的实现,宣告Kimi从LLM/VLM 朝Agent的基本进化已经完成。
时间线:
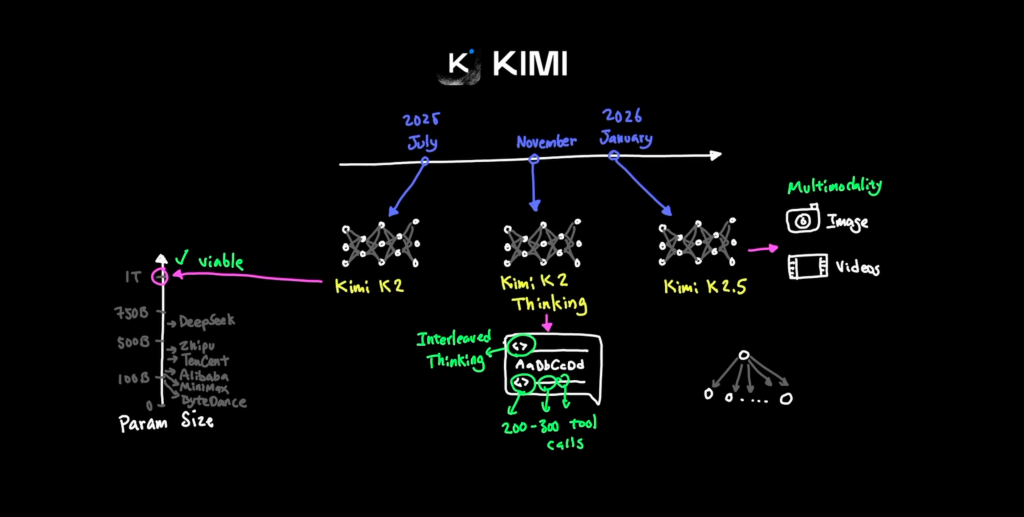
1. 核心提炼
Kimi 2.5 是一个多模态模型,怎么做到多模态的?依赖三点:
(1)joint text-vision pre-training;
- 这个部分显著地变化是:并不是把vision的embedding放到llm模型中,而是在训练早期就进行按照比例的融合。
(2)zero-vision SFT;
- 这个其实就是在微调阶段,不带vision数据玩儿,只用文本数据微调。
(3)joint text-vision reinforcement learing;
- 关键发现:Crucially, we find visual RL enhances textual performance rather than degrading it
同时,kimi 2.5 引入了Agent Swarm功能:一个具有编排并行Agent 能力的框架,这个框架可以将复杂的任务拆分成混合的子任务,然后并行执行。
实验证明,与业界的几个顶尖闭源模型相比,Kimi K2.5效果不错:

BrowseComp = Browser Competency Benchmark(浏览器能力基准测试),测试的是Agents的能力。
在笔者自己团队的业务benchmark中,Kimi K2.5 取得的效果整体与Qwen3-235B-A22B-Instruct 差不多。
简言之Kimi K2.5 的关键改进,就两点:联合的文本、视觉训练 + Agent Swarm 的创新。下面就针对这两点,详细地展开叙述。
2. 图文联合优化训练
- Kimi K2.5 原生的多模态大模型,在15万亿图文token下训练得到。其实现在业界还没有对图文混合训练的方式形成共识。正如文中所说:
A key design question for multimodal pre-training is: Given a fixed vision-text token budget, what is the optimal vision-text joint-training strategy.
kimi2.5 的这种做法并非业界最新,目前来看,Native Multimodal Pretraining 已经是现在业界比较通用的做法了。比如qwen3系列就是这么做的。

之前的工作:比如qwen3vl/seed1.5vl 都是在LLM训练偏后的阶段,以一个比较大的比例(50%或者更高)来加速多模态能力的获取,将多模态能力视为在语言能力基础上的事后附加(或:事后追加的补充)。
kimi团队给出了一个消融实验:

这个实验看似简单,实际上是大几十万、甚至几百万的成本。这个实验表明一个道理:
- 越早做融合,但是需要用比较低的配比,对模型效果的提升越有效。
Zero-Vision SFT
在预训练完成后,接着就做了这个Zero-Vision SFT 操作。目的是为了让模型有一定的Agent能力。
仅做过预训练的模型没有function call的能力。但又急需这种能力,却又没有图+文=>Function call的这类数据,所以只好用text 类型的数据来做这件事儿。
联合的多模态强化学习
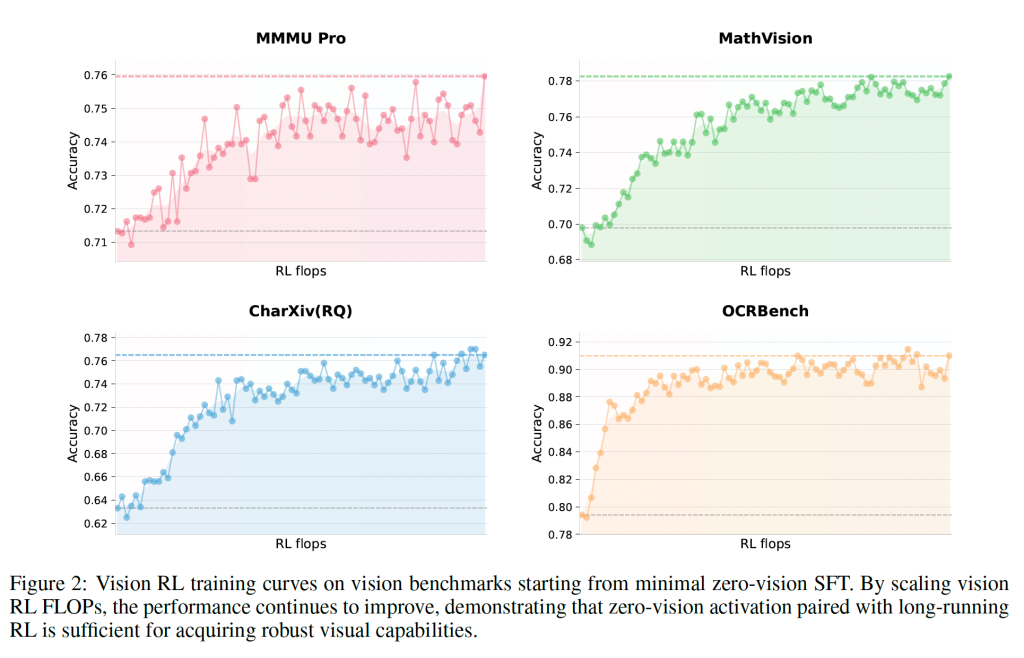
用过qwen2.5-vl/3vl的朋友肯定都有一种体验,就是模型有的时候就是不通过图片内容来判断、理解问题。为了解决这一弊端,Kimi团队提出了一种叫做结果导向的RL方法。这种RL方法主要用于三种场景:
- Visual grounding and counting
- Chart and document understading
- Vision-critical STEM problems
这三种场景都有一个显著的特征就是:解决用户的问题必须依赖图片内容。实验证明,这个方式的效果还是比较明显的:
同时,给出了在Vision-RL 前后,纯文本benchmark上的能力提升对比:
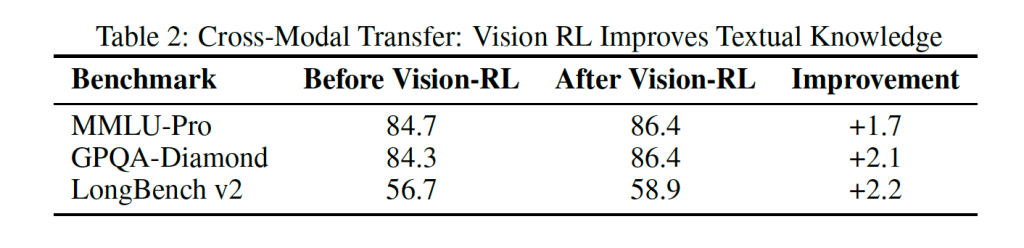
RL的一个典型的特征就是:泛化能力贼强。
3. Agent swarm
Kimi 2.5中最突出的功能就是这个。本质上就是支持多个Agent 编排的框架。为了训练这个Agent Swarm,提出了一个 Parallel-Agent Reinforcement Learning (PARL),这种范式与之前的传统的智能体RL有区别,新增了:(1)子Agent创建;(2)任务委派等训练目标。
orchestrator:编排器

训练orchestrator 编排器是一个非常复杂的过程,所以定义了一个奖励函数如下:

- 是一个用于控制并行的程度的奖励;
- 是一个用于计算sub-agent 任务完成程度的奖励;
- 是任务级的输出结果
To ensure the final policy optimizes for the primary objective, the hyperparameters λ1 and λ2 are annealed to zero over the course of training.
对于这段话,其实不太好理解,如果λ1 与 λ2 缩小至0,那么怎么去奖励这个并行程度呢?我解释一下:
1. 训练初期:用 $\lambda_1$ 避免“串行崩溃 (Serial Collapse)”
训练一个可靠的并行编排器(orchestrator)很难。在训练刚开始时,模型为了稳妥,倾向于陷入一个局部最优解——只使用单智能体串行执行(serial collapse)。为了打破这个僵局,引入了 这个实例化奖励。这时候 $\lambda_1$ 是一个大于 0 的值,相当于给模型发“补贴”,强行鼓励它:“去尝试拉起多个子智能体并发执行吧,只要你敢于探索并发,我就给你分。”
2. 训练后期:退火为 0,回归真实业务目标
随着训练的推进,编排器已经学会了如何调度并发空间。这时候如果 $\lambda_1$ 还不降为 0(比如保持在 1),模型就会学会“钻空子(Reward Hacking)”——为了刷这个并行的奖励分,哪怕当前的任务很简单,根本不需要并发,它也会强行拉起一堆毫无意义的子智能体。
但当系统逐渐成熟后,你就必须把这种“为并发而并发”的奖励撤掉(退火至 0)。因为系统的最终核心目标(也就是公式里的 $r_{\text{perf}}(x,y)$,Task-level outcome)是策略的质量。撤掉 $\lambda_1$ 后,主控 Agent 才能真正根据业务需求去自主判断:当前这个商家画像的生成,到底需要几个 Agent 协作?它会自发地寻找效率和质量的最佳平衡,而不是被辅助指标绑架。
所以,$\lambda_1$ 和 $\lambda_2$ 就像是教小孩骑自行车时的“辅助轮”,学会了之后(退火到 0)就得拆掉,这样才能骑得又快又稳。
Critical Steps as Resource Constraint
为了衡量计算的时间消耗,添加了一个 critical step 用于计算度量。计算公式如下:
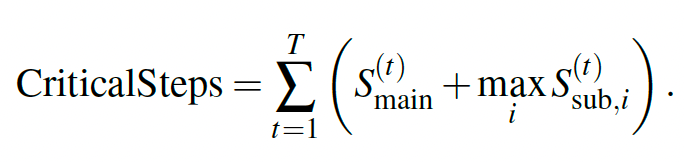
4. 架构一览
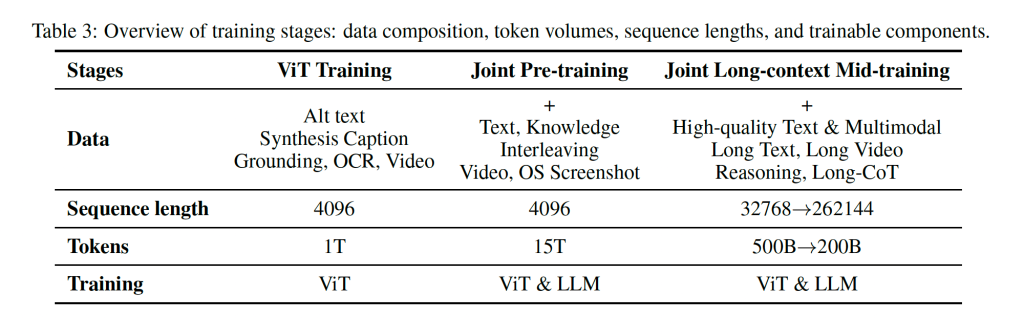
整个训练的阶段:
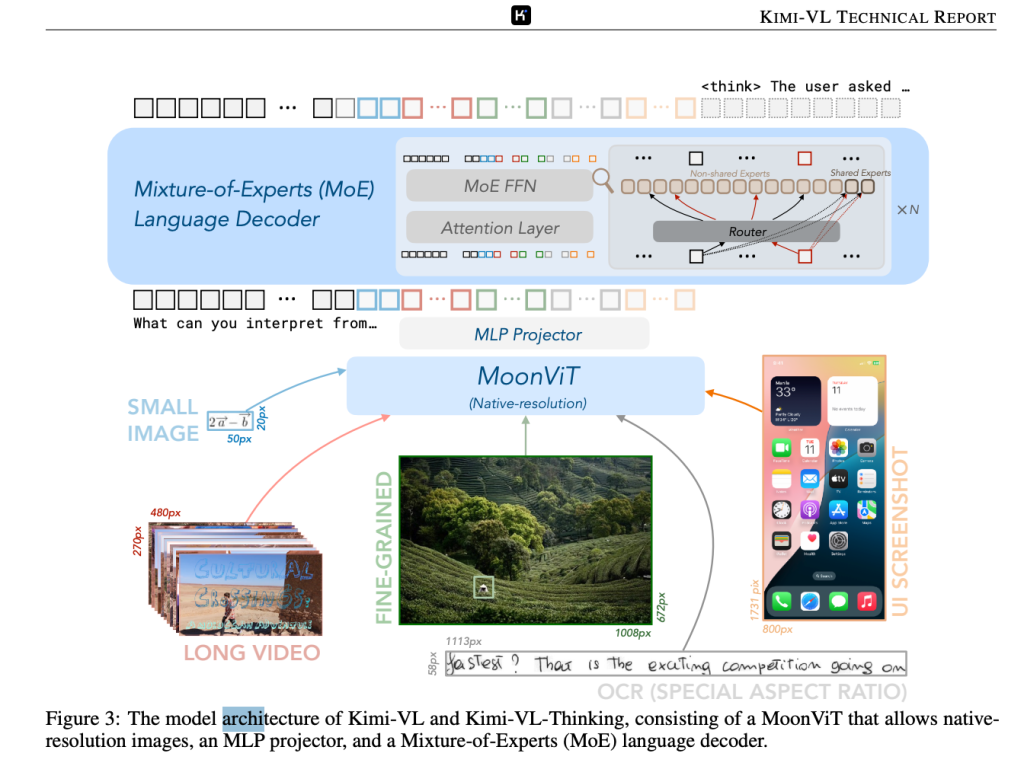
整个Kimi K2.5 的多模态架构包括3个部分:一个三维的原生分辨率视觉编码器(MoonViT-3D),一个MLP的projector;一个Kimi K2 MOE 的LLM。整体架构跟Kimi vl 相似,如下所示:
预训练
- 基于Kimi K2 的checkpoint;
- 三个阶段合计训练15T tokens;
- 第一,单独的ViT 训练,用于建立一个鲁棒的原生分辨率的编码器;
- 第二,联合的预训练,用于同时提升语言和视觉的能力;
- 第三,用于提升长上下文下的模型能力,这部分文章里面称作是mid-training;
后训练
监督微调
使用多个模型合成的数据来做SFT。模型包括:
- K2
- K2 Thinking
- 一系列的内部专家模型
同时,针对不同的领域,有不同的生成策略,同时包含了人工标注,高级的prompt工程,多阶段验证等。
这种方法得到了大规模的指令调优数据,这些数据有着各种不同的prompts,复杂的推理轨迹。
强化训练
强化训练是后训练中的关键部分。对于不同任务设计了不同的奖励函数。对于通用任务使用的是通用奖励函数GRMs(Generative Reward Models)。
生成式奖励模型(Generative Reward Models)
Kimi K2 采用了一种针对开放生成任务的“自我批判”评分标准奖励机制,而 K2.5 在此工作基础上进一步拓展,系统性地将生成式奖励模型(GRMs)应用于广泛的智能体行为和多模态轨迹中。我们并未将奖励建模局限于对话输出,而是将其扩展到多种环境中的已验证奖励信号之上,包括聊天助手、代码智能体、搜索智能体以及生成产物的智能体。
值得注意的是,GRMs 并非作为简单的二元裁决者发挥作用,而是作为与 Kimi 核心价值观对齐的细粒度评估器,这些价值观对用户体验至关重要,例如:有用性、响应及时性、上下文相关性、细节详略得当、生成内容的审美质量,以及严格遵循指令等。这种设计使得奖励信号能够捕捉到基于纯规则或特定任务验证器难以编码的细微偏好梯度。
为了缓解奖励劫持(reward hacking)和对单一偏好信号的过拟合问题,我们采用了多个针对不同任务场景量身定制的 GRM 评分标准(rubrics)。
Toggle
这也是一种强化学习的方法,是Kimi 2.5的一个重要创新。背景是:团队观察到一种叫做length-overfitting 的现象:在严格预算约束下训练的模型往往难以泛化到更高计算规模的场景。大白话就是:过惯了苦日子(token受限),在有钱的时候(token量不限制输出的情况下)不知道怎么花钱了。
于是Kimi团队针对不同的训练阶段使用了不同的强化方法。
训练架构
这部分不是很懂,暂时不做介绍了。